pdf-mcp
by jztan·★ 35·综合分 47
MCP 服务器让 AI 智能体能够分块读取、混合搜索、OCR 识别并提取 PDF 内容,使用 SQLite 缓存提高性能。
概述
pdf-mcp 是基于 Python 和 PyMuPDF 构建的专业 MCP 服务器,为 AI 智能体提供高效的 PDF 内容访问功能。它通过允许智能体读取特定页面或范围,而非加载整个文档,解决了上下文窗口限制问题。服务器实现了混合搜索,结合 BM25 关键字和通过倒排等级融合(RRF)的语义搜索,具备扫描文档的 OCR 功能、表格和图像的结构化提取,以及基于 SQLite 的持久缓存。它具备强大的安全性,采用仅 HTTPS 的 URL 获取和 SSRF 防护。
试试问 AI
装完之后,这里有 5 个你可以让 AI 做的事:
什么时候选它
当您需要为AI代理提供全面的PDF处理功能时,特别是对于需要分块阅读、混合搜索和OCR支持的大文档时,选择pdf-mcp。
什么时候不要选它
如果您需要加密PDF支持、实时协作PDF编辑或超出图像范围的高级多媒体处理功能,不要选择pdf-mcp。
此 server 暴露的工具
从 README 抽取出 8 个工具pdf_infoPage count, metadata, TOC summary, scanned-page detection. Call first.
pdf_get_tocFull table of contents for documents with >50 bookmarks
pdf_read_pagesRead specific pages or ranges; OCR-on-demand; embedded images + tables
pdf_read_allRead entire document in one call (byte-capped for safety)
pdf_render_pagesRender pages as PNG for vision models — diagrams, handwriting, scans
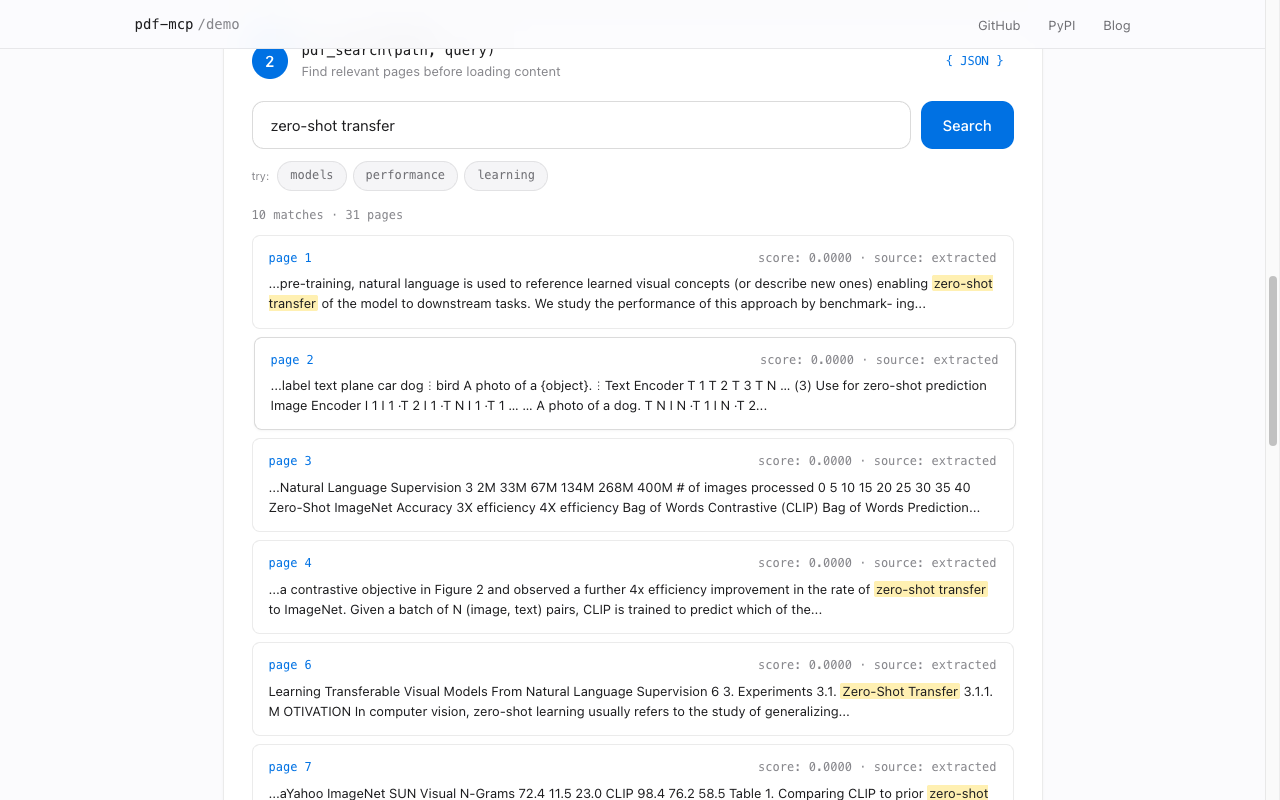
pdf_searchHybrid RRF search (keyword + semantic), page or section granularity
pdf_cache_statsPer-document cache breakdown + total size
pdf_cache_clearClear expired or all cache entries
可对比工具
安装
pip install pdf-mcp对于 Claude Desktop,添加到 claude_desktop_config.json:
{
"mcpServers": {
"pdf-mcp": {
"command": "pdf-mcp"
}
}
}FAQ
- pdf-mcp 如何处理大型 PDF 文档?
- pdf-mcp 使用分块读取功能,允许 AI 智能体读取特定页面或页面范围,而不是加载整个文档,从而防止上下文溢出问题。
- pdf-mcp 提供哪些搜索功能?
- pdf-mcp 使用倒排等级融合(RRF)结合 BM25 关键字搜索和语义搜索,提供更全面的文档查询能力。
pdf-mcp 对比
最后更新于 · 由 README + GitHub 公开数据自动生成。