cuba-memorys
by LeandroPG19·★ 22·Score 45
A sophisticated MCP server providing AI agents with persistent memory using knowledge graphs, neuroscience-inspired algorithms, and anti-hallucination techniques.
Overview
Cuba-Memorys is a comprehensive MCP server that implements advanced memory features for AI agents, including a knowledge graph with typed relations, Hebbian learning, and exponential importance decay. The server offers 23 tools for memory management, hybrid search capabilities using RRF fusion, contradiction detection, and prospective memory triggers. It features a PostgreSQL backend with automatic Docker provisioning, making it easy to set up and use in various environments. The implementation demonstrates strong technical rigor with 97 tests, zero clippy warnings, and regular updates with new features like project scoping and LLM-judged contradiction resolution.
Try asking AI
After installing, here are 5 things you can ask your AI assistant:
When to choose this
Choose Cuba-Memorys when you need neuroscience-inspired persistent memory with advanced features like knowledge graphs, contradiction detection, and anti-hallucination grounding for AI agents.
When NOT to choose this
Not suitable if you need a simple memory solution without heavy dependencies, or if you require a non-CC BY-NC 4.0 licensed solution for commercial use.
Tools this server exposes
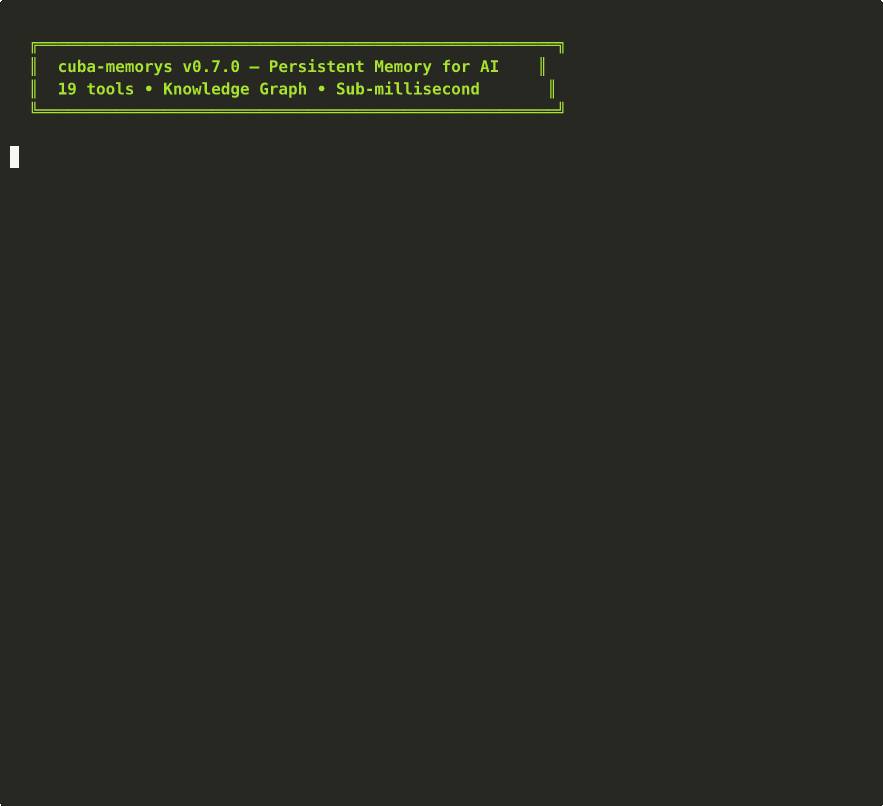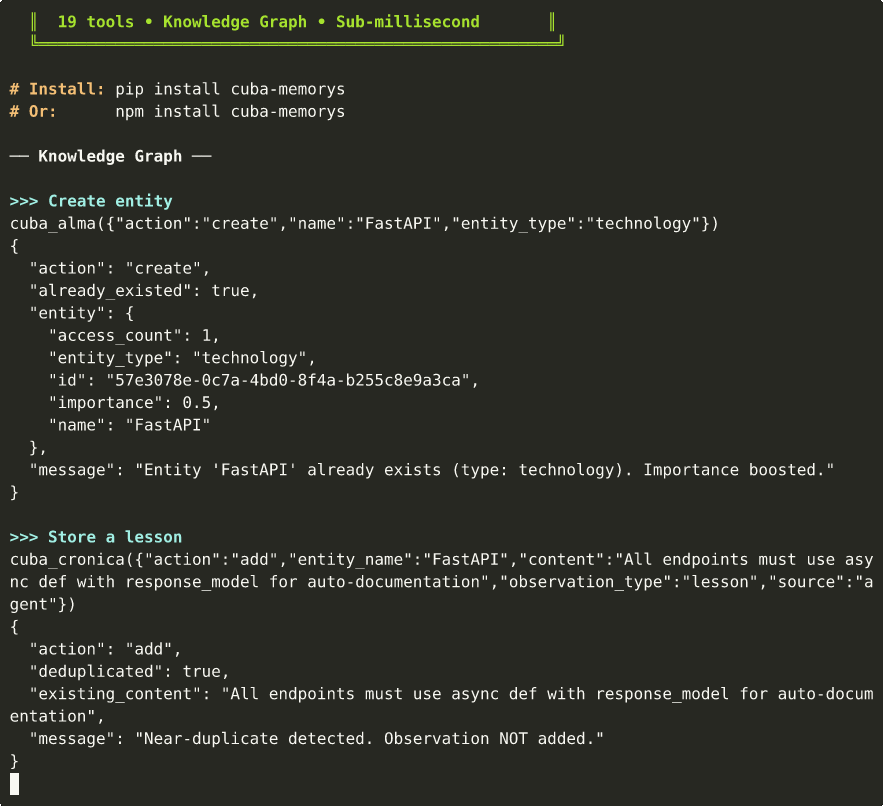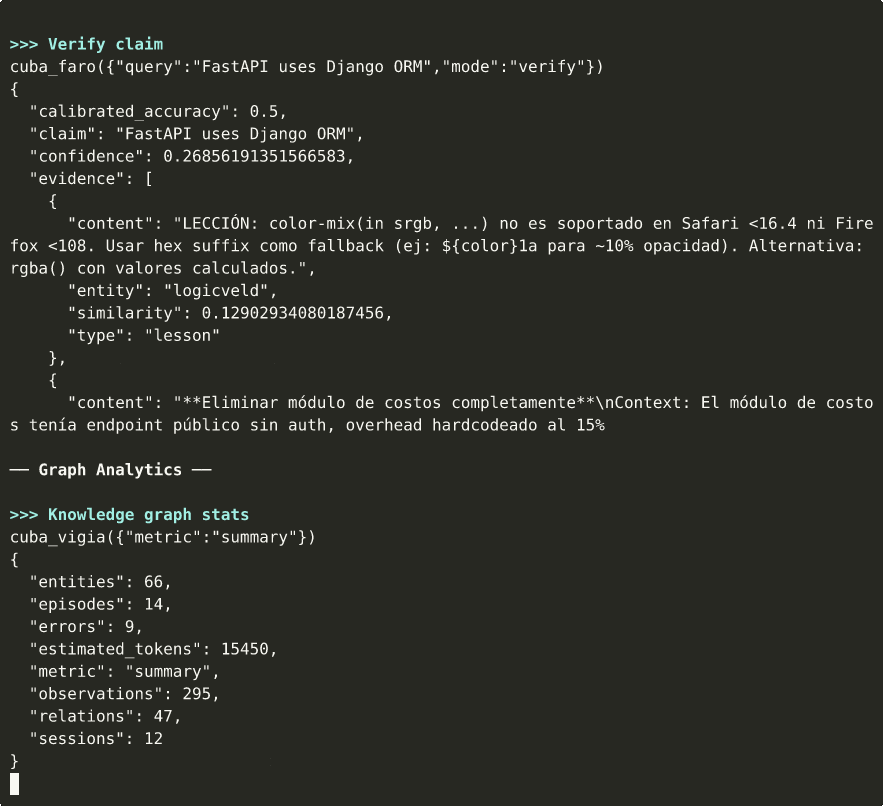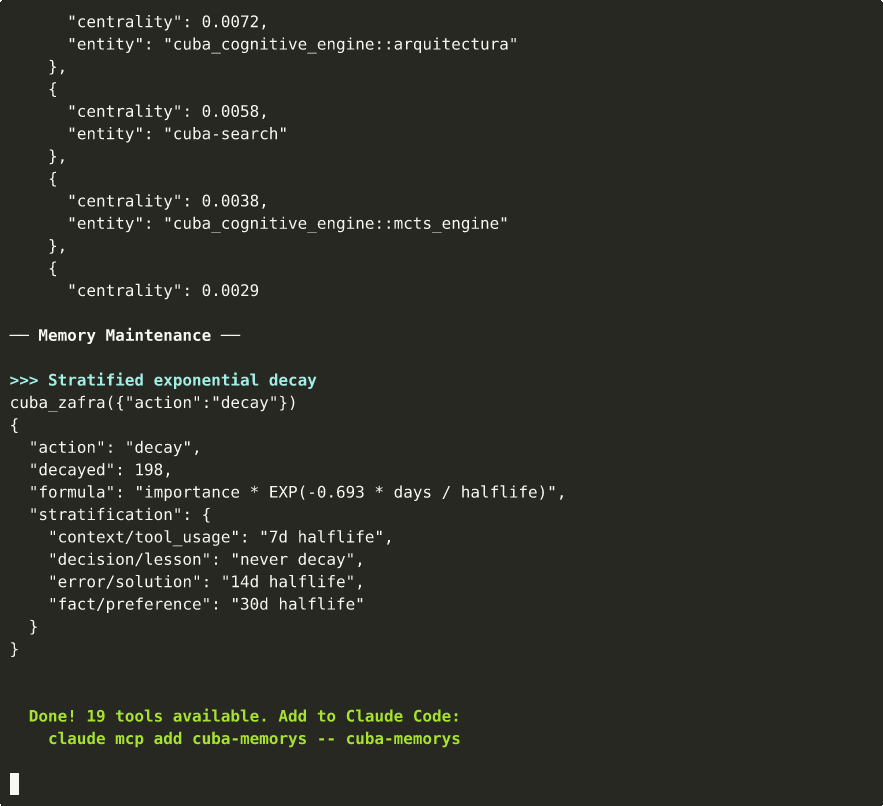
12 tools extracted from the READMEcuba_almaCRUD entities with Hebbian boost + access tracking. Fires prospective triggers on access.
cuba_cronicaObservations with semantic dedup, auto-tagging, session provenance, and contextual embedding.
cuba_puenteTyped relations. Traverse walks the graph. Infer discovers transitive paths. Predict suggests missing relations.
cuba_ingestaBulk knowledge ingestion: arrays of observations or long text with auto-classification.
cuba_faroRRF fusion search with entropy routing, temporal filters, tag filters, and score breakdown.
cuba_sueñoREM sleep consolidation: stratified decay + PageRank + auto-prune + auto-merge + episode decay.
cuba_zafraDecay memories with testing effect: halflife scaled by access count frequency.
cuba_proyectoIsolate memories per project. List projects and manage project-scoped memories.
cuba_juezEscalate ambiguous-similarity observation pairs to LLM judge for contradiction resolution.
cuba_calibrarBayesian calibration of source credibility with Beta(α,β) updates.
cuba_syncExport memories in git-friendly format or import idempotently.
cuba_faroSearch with BM25 hybrid 3-way fusion, MMR diversification, and OOD abstention.
Comparable tools
Installation
Recommended Installation (PyPI)
pip install cuba-memorysClaude Desktop Configuration
Add to Claude Desktop config:
{
"mcpServers": {
"cuba-memorys": {
"command": "cuba-memorys"
}
}
}Auto-provisioned Setup
No configuration required - the server automatically provisions a PostgreSQL database via Docker on first run. Docker must be installed and running.
Custom PostgreSQL Setup
If you already have PostgreSQL with pgvector:
{
"mcpServers": {
"cuba-memorys": {
"command": "cuba-memorys",
"env": {
"DATABASE_URL": "postgresql://user:pass@localhost:5432/brain"
}
}
}
}FAQ
- What makes Cuba-Memorys different from basic memory MCP servers?
- Cuba-Memorys implements advanced features like knowledge graphs with typed relations, Hebbian learning, hybrid RRF fusion search, graph intelligence analytics, contradiction detection, and neuroscience-inspired memory consolidation algorithms that are not found in basic memory implementations.
- How does the server handle data persistence?
- The server uses PostgreSQL as its backend with pgvector for vector storage. It can automatically provision a Docker container with PostgreSQL on first run, or connect to an existing PostgreSQL instance. Data is maintained across sessions with various decay mechanisms and consolidation processes.
Compare cuba-memorys with
Last updated · Auto-generated from public README + GitHub signals.