pdf-mcp
by jztan·★ 35·Score 47
MCP server enabling AI agents to read, search, and extract content from large PDFs with chunked reading, hybrid search, OCR, and SQLite caching.
Overview
pdf-mcp is a specialized MCP server built with Python and PyMuPDF that provides AI agents with efficient access to PDF content. It solves the context window limitation problem by allowing agents to read specific pages or ranges rather than loading entire documents. The server implements hybrid search combining BM25 keyword and semantic search via Reciprocal Rank Fusion, OCR capabilities for scanned documents, structured extraction of tables and images, and persistent SQLite-based caching. It features robust security with HTTPS-only URL fetching and SSRF protection.
Try asking AI
After installing, here are 5 things you can ask your AI assistant:
When to choose this
Choose pdf-mcp when you need comprehensive PDF processing capabilities for AI agents, especially for large documents requiring chunked reading, hybrid search, and OCR support.
When NOT to choose this
Don't choose pdf-mcp if you need encrypted PDF support, real-time collaborative PDF editing, or advanced multimedia processing beyond images.
Tools this server exposes
8 tools extracted from the READMEpdf_infoPage count, metadata, TOC summary, scanned-page detection. Call first.
pdf_get_tocFull table of contents for documents with >50 bookmarks
pdf_read_pagesRead specific pages or ranges; OCR-on-demand; embedded images + tables
pdf_read_allRead entire document in one call (byte-capped for safety)
pdf_render_pagesRender pages as PNG for vision models — diagrams, handwriting, scans
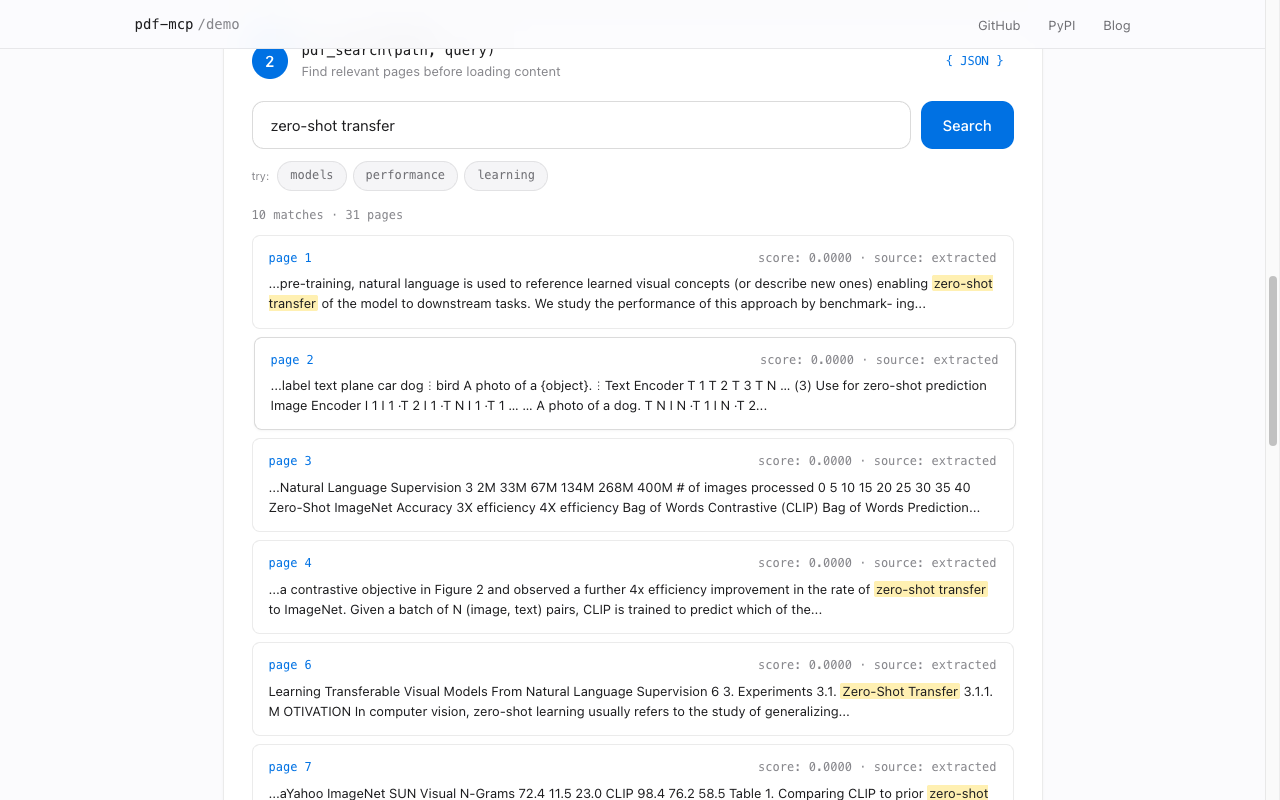
pdf_searchHybrid RRF search (keyword + semantic), page or section granularity
pdf_cache_statsPer-document cache breakdown + total size
pdf_cache_clearClear expired or all cache entries
Comparable tools
Installation
pip install pdf-mcpFor Claude Desktop, add to claude_desktop_config.json:
{
"mcpServers": {
"pdf-mcp": {
"command": "pdf-mcp"
}
}
}FAQ
- How does pdf-mcp handle large PDFs?
- pdf-mcp uses chunked reading, allowing AI agents to read specific pages or page ranges rather than loading entire documents, preventing context overflow issues.
- What search capabilities are available?
- pdf-mcp provides hybrid search using Reciprocal Rank Fusion to combine BM25 keyword search and semantic search, enabling more comprehensive document queries.
Compare pdf-mcp with
Last updated · Auto-generated from public README + GitHub signals.